

Bottom Line: Closing cloud security gaps starting with Infrastructure-as-a-Service (IaaS) and Platform-as-a-Service (PaaS) needs to happen now as cloud services-based cyberattacks have grown 630% since January alone, creating a digital pandemic just as insidious as Covid-19.
Cyberattacks are going through a digital transformation of their own this year, with their targets more frequently being cloud services and the workloads running on them. McAfee Labs Covid-19 Threats Report from July found a 630% increase in cloud services cyberattacks between January and April of this year alone.
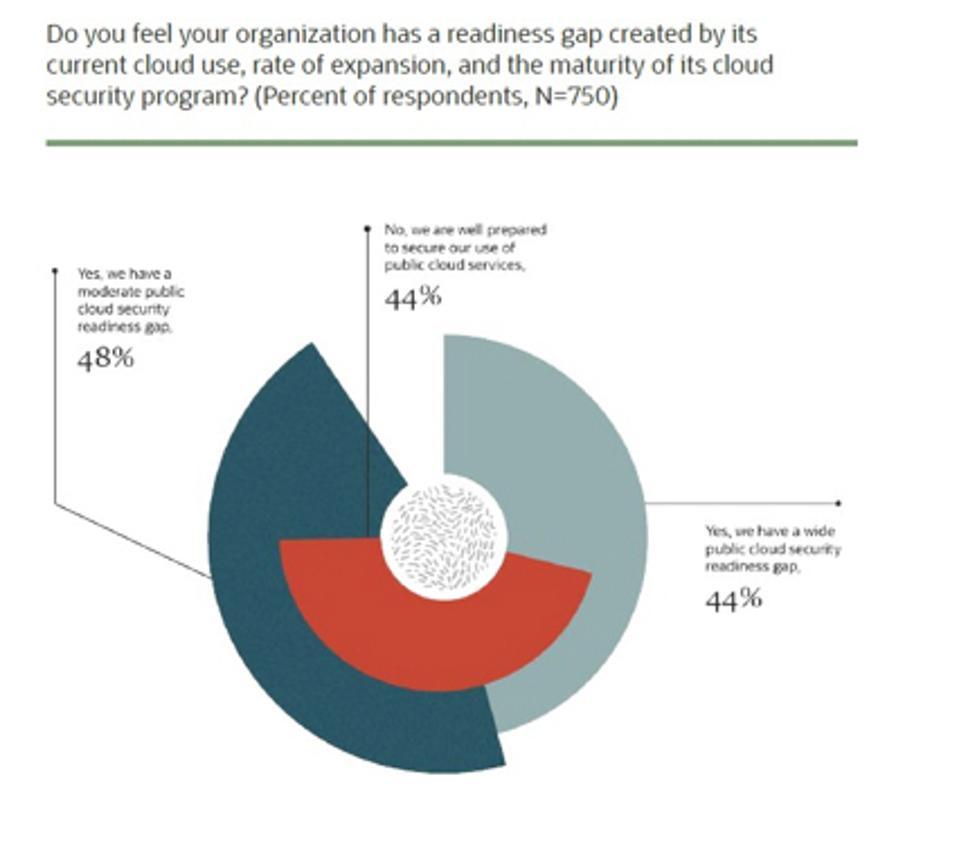
The cyberattacks look to capitalize on opportunistic gaps in cloud platforms’ security structures. The 2020 Oracle KPMG Cloud Threat Report provides insights into much faster cloud migration is outpacing security readiness. 92% of security leaders admitted that their organization has a gap between current and planned cloud usage and their program’s maturity. Of the 92%, 48% say they have a moderate public cloud security readiness gap and 44% say the gap is wider than average. The research team looked at the overlap of which organizations believe they can secure their use of public cloud services and found 44% do today across both categories.
The urgency to close security gaps is amplified by the increasing adoption rate of IaaS and PaaS, with the last three years shown below.

What Are The Fastest Growing Cybersecurity Skills In 2021?Enterprises’ AI & Cybersecurity Needs Are Rejuvenating Mainframes83% Of Enterprises Transformed Their Cybersecurity In 2020
The Oracle KPMG team also found that nearly a third of enterprise applications are either going through or are planned for a lift-and-shift to the cloud, further accelerating the need for better cloud security.
Five Ways Cloud Platforms Need To Be More Secure In 2021
The majority of IT and cybersecurity teams I talk with today are overwhelmed. From troubleshooting remote access for legacy on-premise applications to keeping the queues in their ITSM systems under control, there’s not much time left. When it comes to cybersecurity, the more practical the advice, the more valuable it is.
This week I read Gartner’s recent report, 5 Things You Must Absolutely Get Right for Secure IaaS and PaaS, available as a complimentary read by Centrify. Based on insights gained from the report and ongoing discussions with IT and cybersecurity teams, the following are five ways cloud platforms need to be made more secure in 2021:
- Prioritize Privileged Access Management (PAM) and Identity & Access Management (IAM) using cloud-native controls to maintain least privilege access to sensitive data starting at the PaaS level. By getting access controls in place first, the entire cloud platform is innately more secure. To save time and secure cloud platforms as thoroughly as possible, it’s advisable to utilize cloud-native Privileged Access Management (PAM) solutions that enforce Multifactor Authentication (MFA) and create specific roles admin functions that have a time limit associated with them. Leading vendors offering cloud-ready PAM capabilities include Centrify, which has proven its ability to deploy cloud-based PAM systems optimized to the specific challenges of organizations digitally transforming themselves today.
- Start using customer-controlled keys to encrypt all data, migrating off legacy operating systems and controls that rely on trusted and untrusted domains across all IaaS instances. IT teams say getting consistent encryption across each cloud provider is proving elusive as each interprets the Cloud Shared Responsibility Model differently, given their respective product and services mix. Cloud platform providers offer IAM and PAM tools fine-tuned to their specific platforms but can’t control access across multi-cloud environments. Securing and encrypting data across multiple cloud platforms takes a more centralized approach, providing full logging and audit capabilities that secure audit data from Cloud Service Providers (CSPs).
- Before implementing any cloud infrastructure project, design in Zero Trust Security (ZTS) and micro-segmentation first and have IaaS and PaaS structure follow. Both ZTS and micro-segmentation are pivotal to securing cloud infrastructure today. Think of IAM, ZTS, MFA and PAM as the foundation of a secure cloud infrastructure strategy. Having these core foundational elements in place assures the PaaS layer of cloud infrastructure is secure. As traditional IT network perimeters dissolve, enterprises need to replace the “trust but verify” adage with a Zero Trust-based framework. Zero Trust Privilege mandates a “never trust, always verify, enforce least privilege” approach to privileged access, from inside or outside the network. Centrify is a leader in this area, combining password vaulting with brokering of identities, multifactor authentication enforcement and “just enough” privilege while securing remote access and monitoring all privileged sessions.
- Before implementing any PaaS or IaaS infrastructure, define the best possible approach to identifying, isolating and correcting configuration mistakes or errors in infrastructure. From the basics of scanning unsecured configurations to auditing unsecured ports, every organization can take steps to better identify, isolate and correct infrastructure configuration errors. The fast-growing area of Cloud Security Posture Management (CSPM) is purpose-built to identify misconfigured cloud components across an entire infrastructure. Many IT teams get started with an initial strategy of monitoring and progress to more proactive tools that provide real-time alerts of any anomalous errors. CSPM tools in the most advanced IT organizations are part of a broader cloud infrastructure security strategy that also encompasses web application and API protection (WAAP) applications that ensure external and internal API security and stability.
- Standardize on a unified log monitoring system that ideally as AI and machine learning built to identify cloud infrastructure configuration and performance anomalies in real-time. CIOs are also saying that the confusing array of legacy monitoring tools makes it especially challenging to find gaps in cloud infrastructure performance. As a result, CIOs’ teams are on their own to interpret often-conflicting data sets that may signal risks to business continuity that could be easily overlooked. Making sense of potentially conflicting data triggers false-positives of infrastructure gaps, leading to wasted time by IT Operations teams troubleshooting them. Most organizations have SIEM capabilities for on-premises infrastructures, such as desktops, file servers and hosted applications. However, these are frequently unsuitable and cost-prohibitive for managing the exponential growth of cloud logs. AIOps is proving effective in identifying anomalies and performance event correlations in real-time, contributing to greater business continuity. One of the leaders in this area is LogicMonitor, whose AIOps-enabled infrastructure monitoring and observability platform have proven successful in troubleshooting infrastructure problems and ensuring business continuity. LogicMonitor’s AIOps capabilities are powered by LM Intelligence, a series of AI-based algorithms that provide customer businesses with real-time warnings into potential trouble spots that could impact business continuity
Conclusion
Protecting cloud infrastructures against cyberattacks needs to be an urgent priority for every organization going into 2021. IT and cybersecurity teams need practical, pragmatic strategies that deliver long-term results. Starting with Privilege Access Management (PAM) and Identity & Access Management (IAM), organizations need to design in a least privilege access framework that can scale across multi-cloud infrastructure.
Adopting customer-controlled keys to encrypt all data and designing in Zero Trust Security (ZTS) and micro-segmentation need to be part of the built core cloud infrastructure. Identifying, isolating and correcting configuration mistakes or errors in infrastructure helps to protect cloud infrastructures further. Keeping cloud infrastructure secure long-term needs to include a unified log monitoring system too. Selecting one that is AI- or machine learning-based helps automate log analysis and can quickly identify cloud infrastructure configuration and performance anomalies in real-time.
All of these strategies taken together are essential for improving cloud platform security in 2021.
Source: https://www.forbes.com/sites/louiscolumbus/2020/11/08/five-ways-cloud-platforms-need-to-be-more-secure-in-2021/?sh=a250c1c32960 08 11 20


 [netdata](
[netdata](













