
What is an AI agent, really?
The term is everywhere. Slides, demos, product pages. And depending on who you ask, an agent is anything from a chatbot with tools to something that sounds suspiciously like the Terminator.
* ‘McKinsey challenges graduates to use AI chatbot in recruitment overhaul’ – FT, Jan 14, 20261
Of course, Prof. Andy came in with the science.
Definitions. Models. Maturity curves. Exciting, very.
So we ended up writing this piece – not to add another opinion, but to clarify what an agent actually is, and what it is not. Stripped of hype. Grounded in how real systems behave.
Although is not as exciting as the title image might suggest.
No killer robots (are we sure?). No secret agents.
Mostly hard bread.
But if you care about how AI will actually change companies – not in demos, but in production – this distinction matters.
The rest of this post does exactly that. It starts by explaining why agents matter now, then pins down a precise definition, and finally shows why the real shift is not happening at the model layer, but one level up – where software starts to execute work.
Not glamorous.
But real.
1. Why AI Agents Matter Now
For a long time, progress in gen AI followed a familiar pattern.
Models got bigger.
Benchmarks improved.
Demos became smoother.
But if you look closely at how work is actually done inside companies, very little changed.
People still open tickets, copy data between systems, escalate edge cases by email, and coordinate across tools that were never designed to work together. The intelligence was there, but it lived between applications rather than inside them. Execution remained a human responsibility. (also compare our blog ‘Has MIT Opened Pandora’s Box on AI Being a Bubble?’)
That gap is where AI agents enter – and the topic likely to dominate 2026.
Not as a new interface.
Not as a smarter chatbot.
But as a different execution model for software.
Agents matter now because large language models have crossed a practical threshold. They are not perfect, but they are reliable enough to reason across multiple steps, evaluate intermediate results, and decide what to do next. What they still lack is structure, control, and integration into real systems. Agents provide that missing layer.

OpenAI frames this shift explicitly by defining agents as systems that “independently accomplish tasks on your behalf,” rather than systems that merely generate responses.2 Microsoft’s enterprise documentation makes a similar point, describing agents as long-running, goal-driven processes that operate across tools and workflows instead of inside a single UI.3
This is not an AGI story.
It is an application-layer story.
And it is about what happens once models are “good enough,” but software still doesn’t actually do the work.

2. What Do We Mean by “AI Agent”
The word agent is currently overused to the point of losing precision.
Chatbots are called agents.
Copilots are called agents.
Scripted workflows are called agents.
Even classic automation tools rebrand themselves as “agentic.”
So we need a definition that is not marketing-based, but rooted in what competent people have used for decades: an agent is defined by behavior over time – not by UI or marketing.
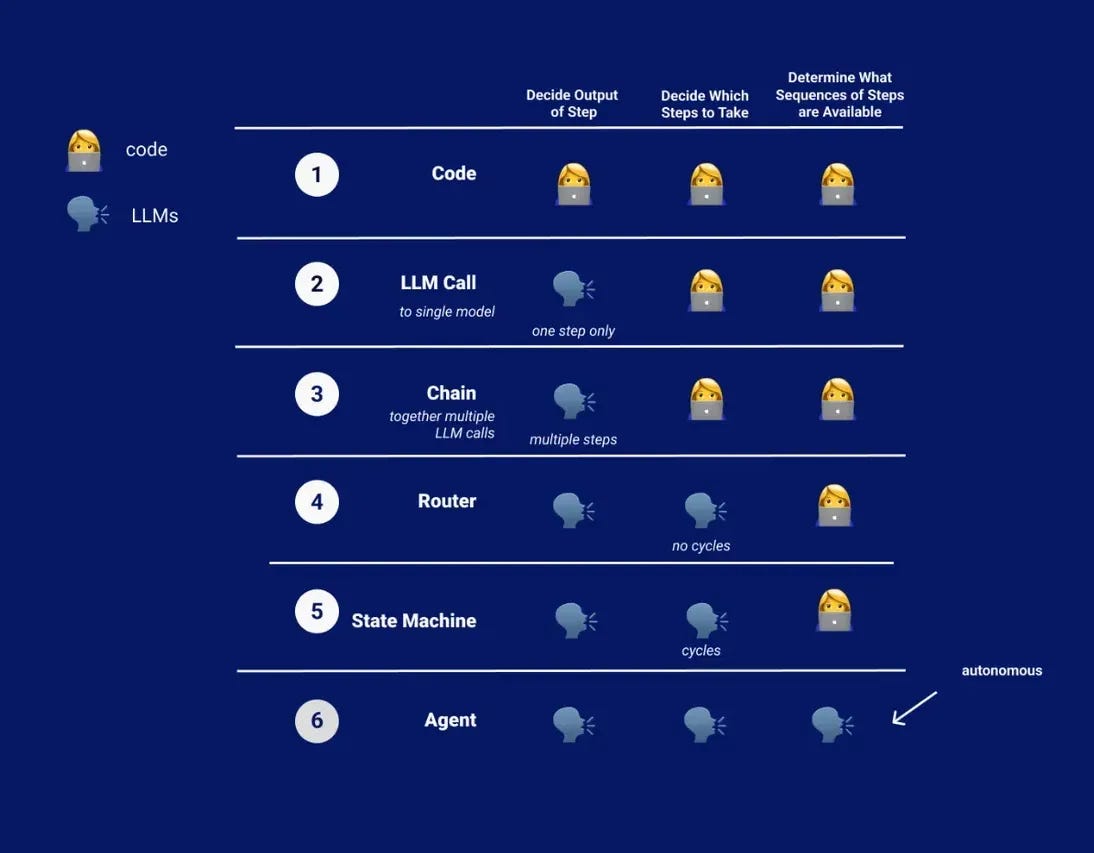
A canonical baseline comes from Russell & Norvig, who define an agent as something that perceives its environment and acts upon it to achieve goals. That framing predates GenAI, and it’s still the cleanest starting point.4 – I know, there are many other definitions.
A working definition (used throughout this series)
For this series, an “AI agent” is a software system that:
- pursues an explicit goal, not just a prompt
- plans across multiple steps, not a single response
- maintains state between steps
- acts through tools (APIs, code, systems)
- evaluates progress and decides whether to continue, adapt, stop, or escalate
This maps well to modern surveys of LLM-based agents that formalize agents as systems composed of objectives, memory, perception, action, and feedback loops rather than simple input–output functions.5
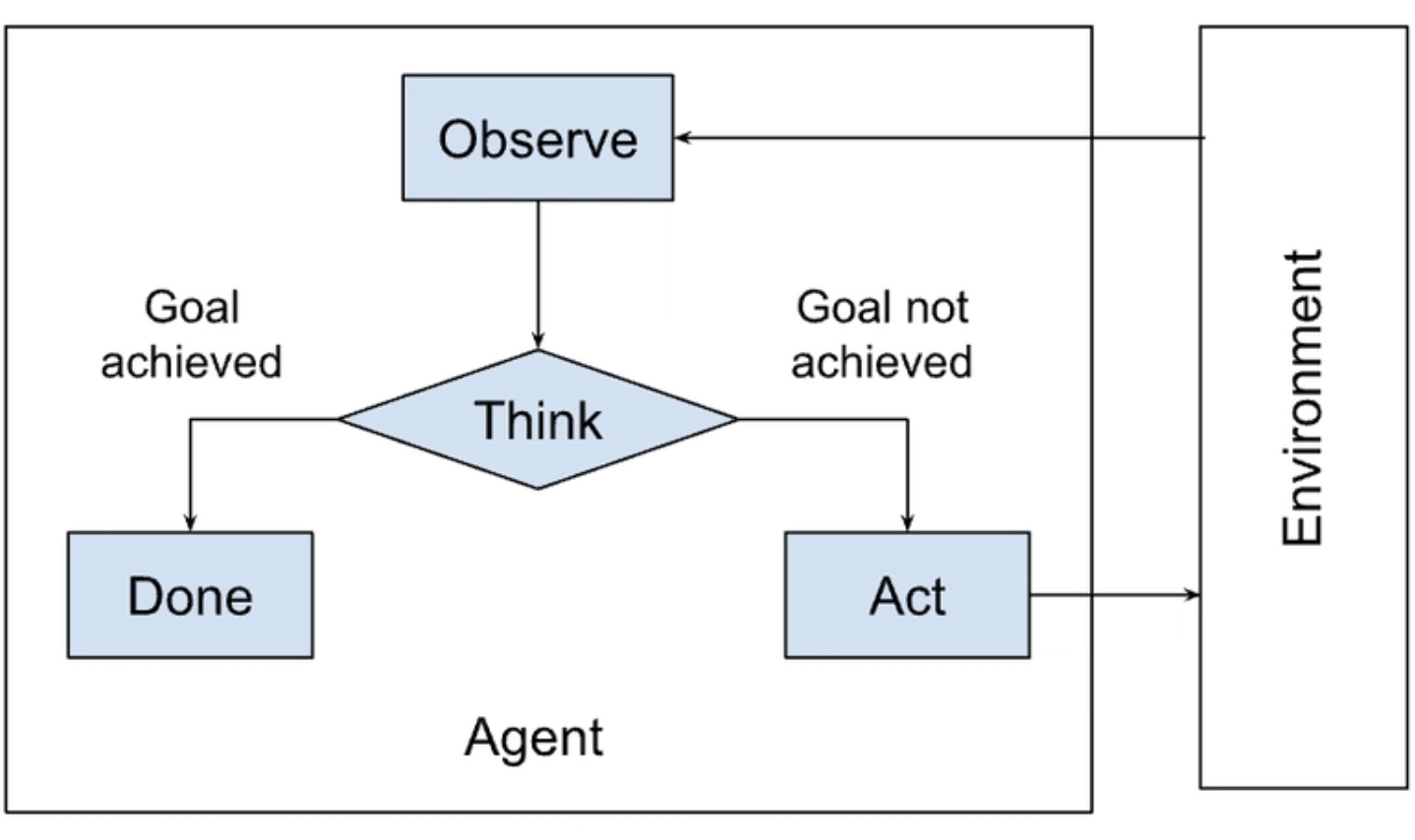
Diagram (agent loop, minimal but precise):
Goal → Plan → Act (Tools) → Observe → Update State/Memory → (repeat until done)
What an agent is not (this matters)
A single LLM call is not an agent.
A chat UI waiting for user input is not an agent.
A static DAG (Directed Acyclic Graph: a fixed, non-looping workflow) is not an agent.6
Pure RAG (Retrieval-Augmented Generation: retrieve → answer → stop) is not an agent.7
Those systems can be useful. But they don’t meet the “behavior over time” definition above. They don’t run work – they answer.
This is also how leading vendor docs frame it in practice. See above.89
Why the term “agent” became confusing
The confusion is that the market uses “agent” for three different things:
- Assistant (helpful interface)
- Workflow (predefined steps, deterministic)
- Agent (goal-driven, stateful, tool-using loop)
If you don’t separate these, you can’t reason about reliability, cost, governance, or failure modes. Everything sounds “agentic” until it breaks.
Diagram (fast comparison):
Assistant: user ↔ chat (help)
Workflow: input → steps → output (deterministic)
Agent: goal → loop → tools → state → completion/escalation (adaptive)
If you want a concrete visual of the “agent as a loop/graph” concept (vs a DAG), LangGraph’s docs and diagrams are among the clearest.10
3. From Apps to Agents: The Real Shift
Traditional software – including modern SaaS – is built on a simple operating assumption:
Humans decide. Software executes.
Users click, select, confirm, and coordinate. Software responds to inputs, but responsibility for outcomes remains with people. Even highly sophisticated systems still rely on humans to interpret context, decide what comes next, and handle exceptions. The intelligence that makes work function lives between applications, embedded in human workflows rather than encoded in software.

This design pattern has been remarkably stable for decades, and it is explicitly reflected in how enterprise software has historically been designed: applications optimize for features and interfaces, not for owning execution end-to-end.
Where apps stop
Applications are optimized around:
- features
- interfaces
- predefined flows

They are good at executing known steps once a human has decided what to do. They are not designed to own the process end-to-end.
As a result, most organizations still depend on people to:
- stitch systems together
- manage handoffs
- resolve edge cases
- take responsibility when things break
Software assists. Humans orchestrate.
This division of labor is exactly what large parts of classic automation and RPA (Robotic Process Automation)11 were built around: deterministic steps, predefined paths, and explicit human control when something unexpected occurs.
What agents change
AI agents invert this relationship.
Instead of waiting for instructions, an agent receives a task. It determines which steps are required, executes actions across tools and systems, evaluates intermediate results, and continues until the task is completed or explicitly escalated.
The unit of interaction shifts:
- from screens and features
- to tasks and outcomes
This is the core structural change. Responsibility moves from people to software — not for judgment yet, but for execution.

This framing is consistent across enterprise documentation. Microsoft explicitly describes agentic systems as orchestration layers that coordinate actions across multiple systems and workflows rather than living inside a single application UI. In this model, agents run long-lived processes that manage state, branching, and tool invocation over time.12
IBM uses similar language when describing enterprise agents, emphasizing systems that evaluate signals, act across domains, and adapt through feedback rather than following fixed scripts. The focus is not conversational interaction, but execution across heterogeneous systems.13
Across vendors, the common thread is not autonomy. It is execution across boundaries.
OpenAI’s own documentation reinforces the same distinction by defining agents as systems that “independently accomplish tasks on your behalf,” explicitly separating them from chat-based assistants that respond turn by turn.14
Why this is not “better automation”
It is tempting to view agents as an incremental upgrade to automation or RPA. That interpretation misses the point.
Traditional automation assumes:
- stable inputs
- predictable paths
- low exception rates
It works best when the process can be fully specified in advance.
Agents are designed for the opposite conditions:
- ambiguous inputs
- changing context
- exception-heavy workflows
They do not eliminate complexity. They absorb it.
This distinction aligns with broader research on automation and AI in organizations, which shows that the limiting factor is rarely intelligence itself, but the ability to handle variability and exceptions in real operational environments.15
What actually shifts inside organizations
When execution moves from apps to agents, the bottleneck changes.
Instead of asking:
- Which feature should we build?
organizations start asking:
- Which tasks can we safely delegate to software? (compare McKinsey above)
This reframing – from feature delivery to task ownership – is exactly what analysts describe as the transition from task automation to autonomous or semi-autonomous workflows.16
This is the inflection point. Not because agents are “smarter,” but because software begins to take responsibility for running work rather than supporting it.
That is the real shift this series is about.
Why this is not “better automation”
It is tempting to view agents as an incremental upgrade to automation or RPA. That interpretation misses the point.
Traditional automation assumes:
- stable inputs
- predictable paths
- low exception rates

It works best when the process can be fully specified in advance.
Agents are designed for the opposite conditions:
- ambiguous inputs
- changing context
- exception-heavy workflows
They do not eliminate complexity. They absorb it.
This is why agents only become viable once reasoning models reach a sufficient level of robustness. Without the ability to reason across steps and adapt to new information, software cannot own execution without constant human intervention.
What actually shifts inside organizations
When execution moves from apps to agents, the bottleneck changes.
Instead of asking:
- Which feature should we build?
organizations start asking:
- Which tasks can we safely delegate to software?
This is the inflection point. Not because agents are “smarter,” but because software begins to take responsibility for running work rather than supporting it.
That is the real shift this series is about.
What changes for leadership
As execution moves from applications to agents, the organizational impact goes one level deeper.
Leadership is no longer managing an organigram made up exclusively of humans. Increasingly, teams consist of humans and agents operating side by side, with agents owning defined tasks, workflows, or execution domains.
This is not speculative. In recent discussions ahead of Davos 2026, McKinsey highlighted that one of the emerging leadership challenges is managing organizations where accountability, coordination, and oversight span both human roles and autonomous or semi-autonomous agents. Traditional org charts assume people in every box. That assumption no longer holds.17

In practice, this introduces new questions:
- Who owns outcomes when an agent executes a task?
- How are responsibilities split between human managers and agent systems?
- Where do escalation paths sit when execution is automated but judgment remains human?
These are organizational design questions, not technology questions. They follow directly from the shift described in this chapter: once software begins to run work, leadership must treat agents as first-class actors in the operating model, not just tools.
This implication will matter more than the technology itself. See also our Blog ‘🦾 AI and Robots – Azeotrope or Entities’.
4. Anatomy of an AI Agent
This is the densest section, and intentionally so. Understanding agents requires looking inside them – not at frameworks or vendors, but at the functional components that repeatedly appear across research and production systems.
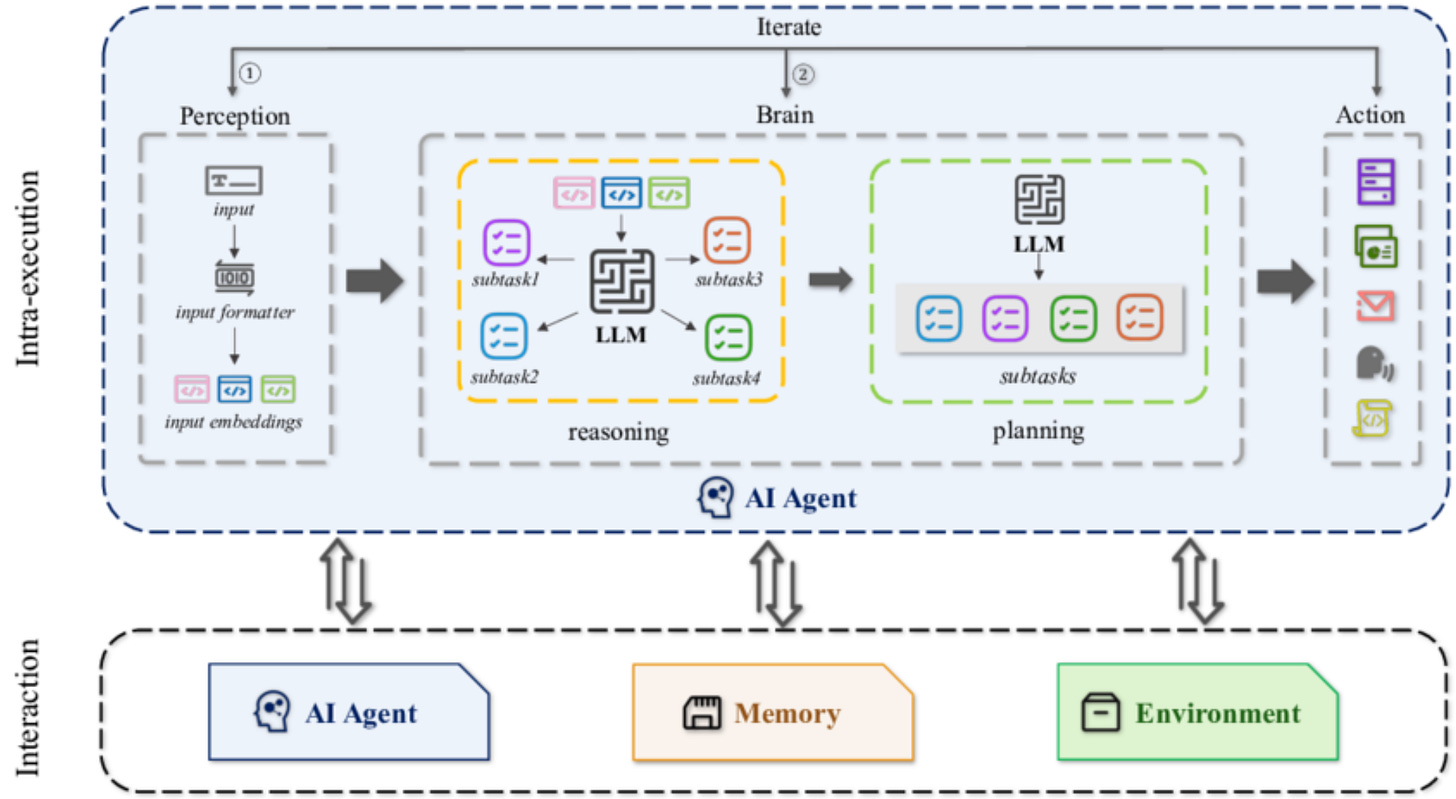
Across the literature, agent architectures converge on a small set of roles. The differences are mostly in implementation, not in structure.
The cognitive core
At the center of an agent sits a cognitive core, typically a large language model or a combination of models. Its role is reasoning and decision-making, not execution.
Early agent systems failed for a predictable reason: they asked the model to do everything – plan, execute, validate, and remember. In practice, this leads to high cost, high latency, and brittle behavior. Empirical work on LLM-based agents shows that conflating reasoning and execution amplifies error propagation and makes systems hard to control.18
Modern agent architectures therefore treat the model as a decision component, not as a controller of the entire system.
Planning vs execution
One of the most widely adopted architectural patterns is the planner–executor split.
The planner determines what should be done.
The executor focuses on how to do it.

This separation reflects a basic operational reality: plans change slowly, while actions happen frequently. By isolating planning from execution, systems reduce reasoning overhead, allow cheaper or specialized models to handle execution, and make failures easier to isolate.
This pattern is formalized in research such as ReAct, which interleaves reasoning and acting while still separating deliberation from tool use, and is now common in production agent frameworks.19
Memory
Memory is another core component – and one of the most common sources of failure.
Agent systems typically rely on:
- working memory, which tracks the current task state and recent actions
- long-term memory, which stores historical context, prior cases, or learned preferences
Retrieval-augmented generation is often used as a memory mechanism, but recent research shows that naïve accumulation of context leads to stale state, uncontrolled growth, and compounding errors in long-running agents.20

Effective agent design treats memory as a managed resource, not as an ever-growing transcript.
Tools and execution
Tools are where agents become operational.
APIs, databases, code execution environments, and internal systems allow agents to act on the world rather than merely describe it. Across real deployments, tool misuse is the dominant failure mode – not model hallucination.
This is why production-grade agent systems emphasize:
- explicit schemas
- input and output validation
- permissioning and access control
These controls matter more for reliability than prompt sophistication. An agent without tools is a reasoning system. An agent with poorly constrained tools is a risk surface.
Feedback and evaluation
Finally, agents require feedback.
Reflection loops, critics, and evaluation steps are increasingly standard in agent architectures because systems without feedback drift over time. Explicit evaluation allows agents to detect failure, trigger retries or escalation, and support auditability.
Research on agent reliability consistently shows that feedback mechanisms are a prerequisite for control in probabilistic systems.21
Without feedback, agents either act too cautiously to be useful or too confidently to be trusted.
Why this matters
These components – reasoning, planning, memory, tools, and feedback – are not optional. They define whether an agent can operate beyond toy demos.
They also explain why agent systems feel complex: they are distributed control systems, not chatbots.
This anatomy is the technical foundation for everything that follows.
5. Structure ≠ Decision Capability
At this point, the structure of AI agents is clear.
They plan.
They maintain state.
They call tools.
They execute workflows.
That already marks a real architectural shift.
What it does not imply is decision maturity.
A well-established constraint (not an opinion)
Across analytics and software engineering, decision systems evolve in distinct maturity stages:
- Descriptive: what happened
- Diagnostic: why it happened
- Predictive: what is likely to happen
- Prescriptive: what should be done
Systematic reviews of data & analytics maturity models show that most organizations operate at the first two levels. Reliable prescriptive decision-making is rare and requires stable data, validated models, governance, and ownership — not just advanced tooling.22
This is a maturity problem, not a technology problem.
The same pattern exists in software engineering
The Capability Maturity Model (CMM/CMMI) shows the same dynamic:
systems only become predictable and reliable once processes are defined, measured, and controlled. Early-stage systems may look impressive, but behave inconsistently and depend on ad-hoc intervention. Reliability emerges from discipline, not sophistication.23
What this means for LLM-based agents
Large language models are generative systems.
They produce plausible reasoning based on language patterns.
This makes them effective at:
- summarizing
- explaining
- pattern-matching
- limited, constrained diagnosis
By default, they do not deliver validated, repeatable prescriptive decisions.
This assessment aligns with big data and analytics maturity research, which shows that prescriptive systems require validated models, stable pipelines, and governance before decision authority can be delegated to software.24
The practical boundary (this matters)
Across real deployments, a consistent pattern appears:
Many agents are structurally capable but operationally immature.
Prescriptive agent behavior becomes defensible only when one of two conditions is met:
- decisions are backed by validated ML or optimization models, or
- the agent is tightly constrained by workflows, guardrails, and human approval points
Without this, agents may execute – but they execute without decision authority.
Why this matters for the rest of the series
AI agents are execution mechanisms.
Their reliability is determined by:
- data maturity
- process discipline
- governance
not by how convincing their reasoning sounds.
Closing of Part 1
So far, we have deliberately avoided discussions about enterprise rollout, economics, labor impact, or governance.
Part 1 is about establishing a shared mental model: what an AI agent actually is, how it differs from apps and workflows, and which components truly matter. Without this foundation, debates about ROI or disruption quickly dissolve into hype or confusion.
With it, we can now turn to the harder questions: why agents are difficult to run in production, where they actually work today, and where their limits still are. Planned for next week.
Sources
Source: OpenAI — Agents guide
Source: https://arxiv.org/abs/2308.11432
Source: https://arxiv.org/abs/2404.04834
Source: https://arxiv.org/abs/2303.11366
Publisher page (Schmalenbach Journal of Business Research, Springer):
https://link.springer.com/article/10.1007/s41471-024-00205-2
DOI:
https://doi.org/10.1007/s41471-024-00205-2
Open-access PDF (via Springer):
https://link.springer.com/content/pdf/10.1007/s41471-024-00205-2.pdf
Canonical source (IEEE Software):
https://ieeexplore.ieee.org/document/219617
IEEE Xplore (conference paper):
https://ieeexplore.ieee.org/document/8970866
Source: https://studioalpha.substack.com/p/ai-agents-when-software-starts-running by Fabian Hediger – 15 Januari 2026
